Structured Topic and Sentiment Analysis Pipeline - Group Transitions Dynamics and Emotional Triggers
An advanced NLP pipeline for structured topic and sentiment analysis, leveraging large language models (LLMs), zero-shot labeling, and hierarchical clustering to decode emotional triggers and semantic patterns in online communities for scalable insights.


Overview
In this study, we investigated the dynamics of online forum groups, focusing on how different groups transition between topics, the emotional and contextual factors influence these shifts.
By leveraging advanced NLP methods and a robust analytical framework, we aimed to uncover patterns in group behavior and emotional triggers that can inform broader social and behavioral studies.
This developed framework was done as part of a large scale psychological study aimed at identifying topic specific and emotional transition factors of groups with different inherent biases.
The Problem
Understanding group transitions and emotional dynamics in online communities presents a unique challenge due to:
- Complexity of Data: Forum texts vary in length, content, and structure, making traditional analytical methods inadequate.
- Semantic and Emotional Ambiguity: Posts often include nuanced emotional undertones and topic overlaps that are difficult to capture with standard NLP tools.
- Lack of Scalable Solutions: Existing approaches struggle to scale and generalize across diverse datasets.
This study addresses these challenges by developing an NLP pipeline capable of processing large-scale forum data while ensuring high granularity, emotional fidelity, and analytical rigor.
Problem Analysis
Challenges in Analyzing Online Forums:
- Topic Granularity: Posts often mix multiple topics, making traditional clustering ineffective.
- Emotional Content: Emotion and sentiment analysis are prone to biases, particularly when applied to diverse groups.
- Hierarchical Structures: Forums have layered structures, from individual posts to overarching group themes.
- Interpretability: Ensuring that outputs from machine learning models align with human interpretability and research objectives.
Existing Gaps in current state-of-the-art:
- Inadequate integration of topic clustering with emotional and sentiment analysis.
- Difficulty in capturing transitions between groups and their emotional triggers.
- Limited use of scalable methods for analyzing hierarchical and clustered data.
Our Approach
Pipeline Overview
We developed a comprehensive NLP pipeline tailored for this study, integrating the following key components:
Text Processing and Labeling
- LLM Integration: Using the Mistral7B-OpenORCA model, fine-tuned on ORCA datasets, for zero-shot topic and emotion labeling.
- Grammar Constrained Decoding: Employed EBNF-based GCD to ensure structured, valid JSON outputs.
Hierarchical Topic Clustering
- Semantic Embedding: Topic labels were encoded using SBERT-based models and visualized in 2D using PaCMAP.
- Clustering: Hierarchical density-based clustering was performed with HDBSCAN, refining topic groupings into granular layers.
Emotion and Sentiment Alignment
- Two-Stage Alignment: First, semantic alignment using RoBERTa embeddings; second, clustering emotions and sentiments using Kmodes clustering.
Data Normalization and Statistical Analysis
- Frequency Normalization: Modified TF-IDF for topic frequencies; normalized emotion and sentiment data relative to topics.
- Combined Sentiment Scoring: A sigmoid-based psychometric scale mapped sentiment frequencies to a bipolar scale.
Statistical Modeling
- Mixed Linear Models: Designed to study differences in variable groups and topic clusters.
- Post Hoc Analysis: Conducted pairwise comparisons using Tukey and Bonferroni adjustments.
Technical Description
We leveraged (at that time) the Mistral7B-OpenORCA LLM, fine-tuned on the ORCA reasoning dataset, to perform zero-shot labeling of each post with topic labels aligned to our study objectives. Custom prompts emphasized extracting specific relevant information.
By summarizing each post into condensed topic labels of uniform granularity, the data became more amenable to clustering, addressing challenges posed by varying post lengths and dispersed relevant information. The LLM also extracted predominant emotion labels and classified each post's sentiment as positive, neutral, or negative.
To ensure structured and valid outputs, we guided the LLM using Grammar Constrained Decoding (GCD) with an Extended Backus-Naur Form (EBNF) Context-Free Grammar (CFG). This approach validated each generation step against a state machine parser, pruning inconsistent logits from the transformer's output layer, thus ensuring consistent and correct JSON format outputs.
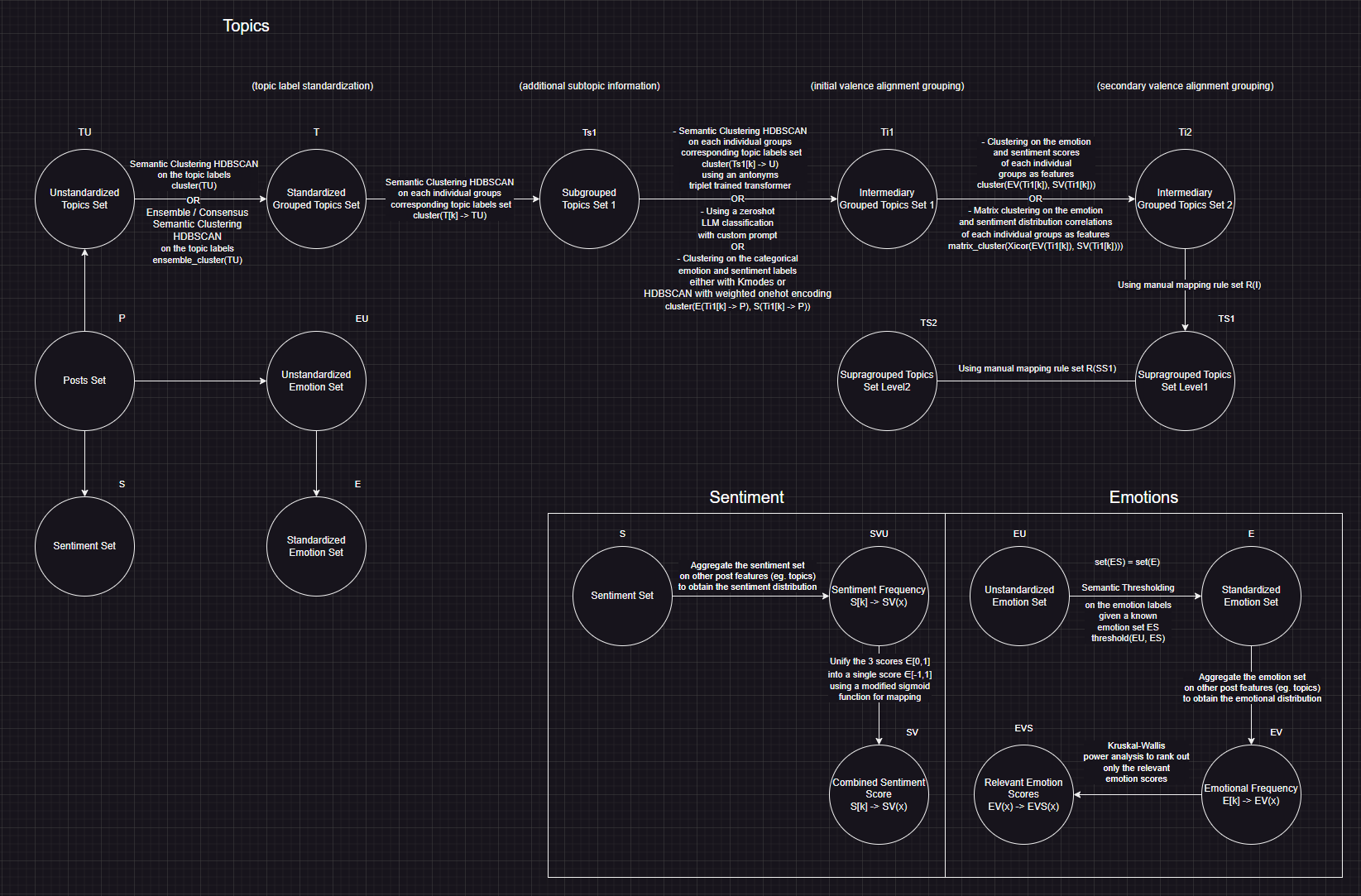
The next phase involved multi-stage semantic clustering of the topic labels, creating a hierarchical structure across multiple layers.

Initially, we aligned topic names between datasets using semantic clustering into "groups," followed by an additional clustering stage for finer granularity into "subgroups." To encode topic labels into semantic vectors for clustering, the study employed the all-MiniLM-L6-v2 SBERT-based embedding model (Red Layers). The topic embeddings were reduced to a 2-dimensional space using PaCMAP, prior to density-based clustering via HDBSCAN. The closest label to each cluster centroid was selected as the representative group label.
Next, we performed a two-stage valence alignment: first (intergroups1), aligning the emotional content embedded in topic labels using a triplet-trained roberta-large-nli-stsb model (Green Layer) with the same PaCMAP and HDBSCAN methods; second (intergroups2), clustering the emotion and sentiment labels for each topic using Kmodes clustering (Yellow Layer) to separate them into two fixed clusters.
We obtained the final analysis set by recursively merging the hierarchical topic groupings into a single flattened layer, then linking it under the supragroupings layer (Blue Layer) - the manually selected output variable groups of the study.
\[ \text{subgroups}_{\text{reduce}} \longrightarrow \text{groups: G'} = \{ { sg \in SG \mid \exists g \in G, \text{ where } sg \text{ is a child of } g } \cup { g \in G \mid \nexists sg \in SG, \text{ where } sg \text{ is a child of } g } \} \]
\[ \text{intergroups1}_{\text{reduce}} \longrightarrow \text{intergroups2: IG'} = \{ { ig2 \in IG2 \mid \exists ig1 \in IG1, \text{ where } ig2 \text{ is a child of } ig1 } \cup { ig1 \in IG1 \mid \nexists ig2 \in IG2, \text{ where } ig2 \text{ is a child of } ig1 } \} \]
\( \text{final\_layer: } G'' = G' \cup IG' \)
\( \text{supragroups} \leftrightarrow \text{final\_layer: } S_{1,2} \to G'' \)
The final flattened topic structure, along with the dataset grouping and the topic and combined sentiment frequencies, was exported in tabular long format for statistical analysis.
We normalized topic frequencies using a modified TF-IDF approach and normalized emotion and sentiment frequencies relative to the topic frequency.
A combined sentiment score was derived from the three independent sentiment frequencies (positive, neutral, negative) using a modified sigmoid function to map them to a single bipolar psychometric scale { [−1, −0.4], [−0.4, 0.4], [0.4, 1] }, akin to how the logistic function is used in Item Response Theory (IRT).
\[ Total=pos+neu+neg \]
\[ \text{Proportion\_Neutral} = \begin{cases} 1, & \text{if } \text{Total} = 0 \\ \frac{\text{neu}}{\text{Total}}, & \text{if } \text{Total} \neq 0 \end{cases} \]
\[ \text{Net\_Sentiment} = (\text{pos} - \text{neg}) \times (1 - \text{Proportion\_Neutral}) \]
\[ \text{Scaled\_Net\_Sentiment} = 5 \times \text{Net\_Sentiment} \]
\[ \text{Sigmoid}(x) = \frac{1}{1 + e^{-x}} \]
\[ \text{Moderated\_Score} = \text{Sigmoid}(\text{Scaled\_Net\_Sentiment}) = \frac{1}{1 + e^{-5 \times \text{Net\_Sentiment}}} \xrightarrow{\text{yields}} [0,1] \]
\[ \text{Final} _{\text{Score}} = 2 \times \text{Moderated} _{\text{Score}} - 1 = \frac{2}{1 + e^{-5 \times (\text{pos} - \text{neg}) \times \left(1 - \frac{\text{neu}}{\text{Total}}\right)}} - 1 \xrightarrow{\text{yields}} [-1, 1] \]
Our statistical analysis employed a mixed linear model (or generalized linear mixed model with a Gaussian kernel), suitable for clustered data and hierarchical structures with defined individual independence modeled via mixed effects. The chosen approach was a simplified model where variables (supragroups) were analyzed separately, discarding potential random effects between variables and considering only the random effect between topic groups within each supragroup.
We defined two model structures: the first to study differences of variables (supragroups) across datasets; the second to analyze differences between topic groups within each variable (supragroup). Each analysis included a subsequent post hoc pairwise comparison using both Tukey and Bonferroni p-value adjustments, with Tukey's method as the default. This analytical methodology was applied first to the topic frequency and then to the combined sentiment score.

Results and Contributions
Key Findings
-
Topic Transition Patterns
- Identified distinct pathways through which groups transitioned between the topics in our control supragroups and extrapolated trends of transitions by comparing the diferently biased corporas.
- Hierarchical clustering revealed significant overlaps and divergences in subgroup behaviors, offering control for separating semantic granularity and aligning the semantic context with the associated sentiment and emotion. -
Emotional Dynamics
- Specific emotions and sentiment scores were strong predictors of group transitions.
- Valence alignment highlighted emotional triggers that frequently initiated topic shifts. -
Scalable Framework
- Demonstrated the effectiveness of the pipeline in analyzing large, unstructured datasets.
- Achieved high interpretability through validated outputs and hierarchical clustering.
Impact on the Field
- Provides a robust methodology for studying behavioral transitions in online forums or any text corpora applicable in domains such as: marketing, mental health, trading, and education..
- Opens avenues for understanding group dynamics in diverse social and professional contexts.
Summary
This study demonstrates the power of advanced NLP techniques in unraveling complex group dynamics and emotional triggers in online forums. By bridging the gap between theoretical research and practical applications, this pipeline lays the groundwork for innovative solutions in behavioral analytics.
To learn more about this approach or explore potential collaborations, contact us.

