Bringing Structure and Faithfulness to LLM Outputs
Exploring Grammar-Constrained Decoding (GCD) for LLMs. Comparing EGG, GAD, and FEG methods for improving efficiency, faithfulness, and flexibility in generating structured output.

Large Language Models (LLMs) are incredibly powerful, capable of generating human-like text, translating languages, and writing different kinds of creative content. However, getting them to reliably produce outputs that follow strict structural rules like valid JSON, formatted code, or specific markup like context-free grammars or EBNFs can be challenging.
How can we guide these powerful models to generate not just any text, but text that conforms precisely to our requirements?
Grammar-Constrained Decoding (GCD)
The classic approach to this problem is Grammar-Constrained Decoding (GCD). Think of it as putting guardrails on the LLM's output.
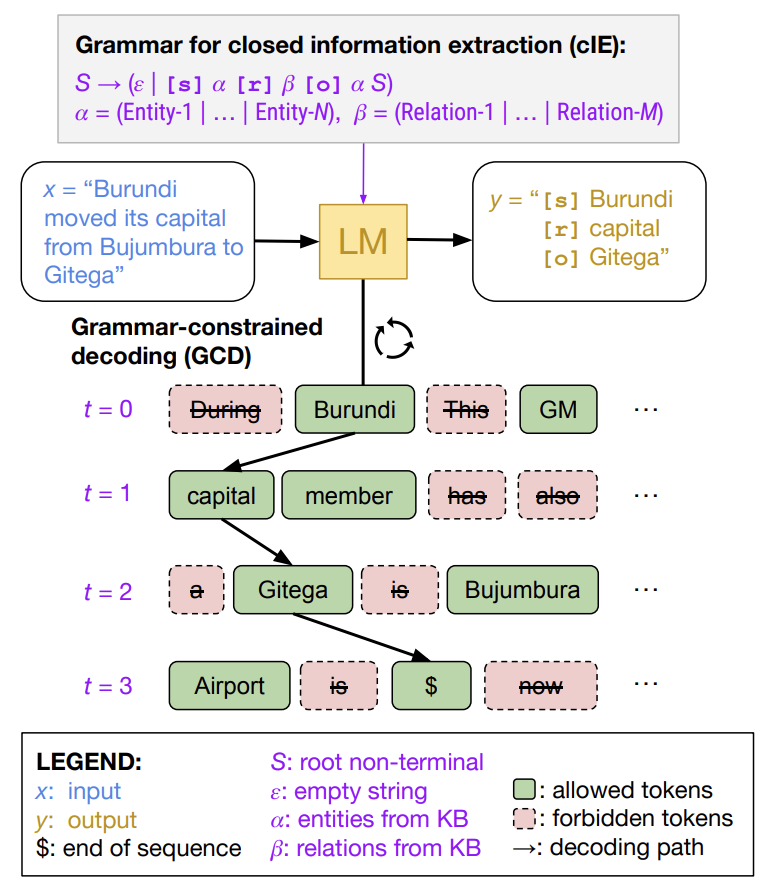
Imagine you want an LLM to generate simple mathematical expressions. At each step, as the LLM considers the next token (e.g., a number, an operator, a parenthesis), GCD checks if adding that token would violate the rules of a valid mathematical expression (defined by a formal grammar). If a token would lead down an invalid path (like putting two operators side-by-side), GCD masks that token, essentially telling the LLM, "Don't pick this one", this is done by essentially hard prunning invalid output logits at each generation step. This ensures the final output always follows the grammar rules.
While effective in guaranteeing structure, classic GCD can be slow. It often needs to check every possible next token against the grammar rules at every single step, which becomes computationally expensive, especially with the massive vocabularies modern LLMs use. Another key challenge is the token misalignment problem.
Making it Faster: Efficient Guided Generation (EGG)
This is where Efficient Guided Generation (EGG) comes in. EGG tackles the efficiency bottleneck of GCD.
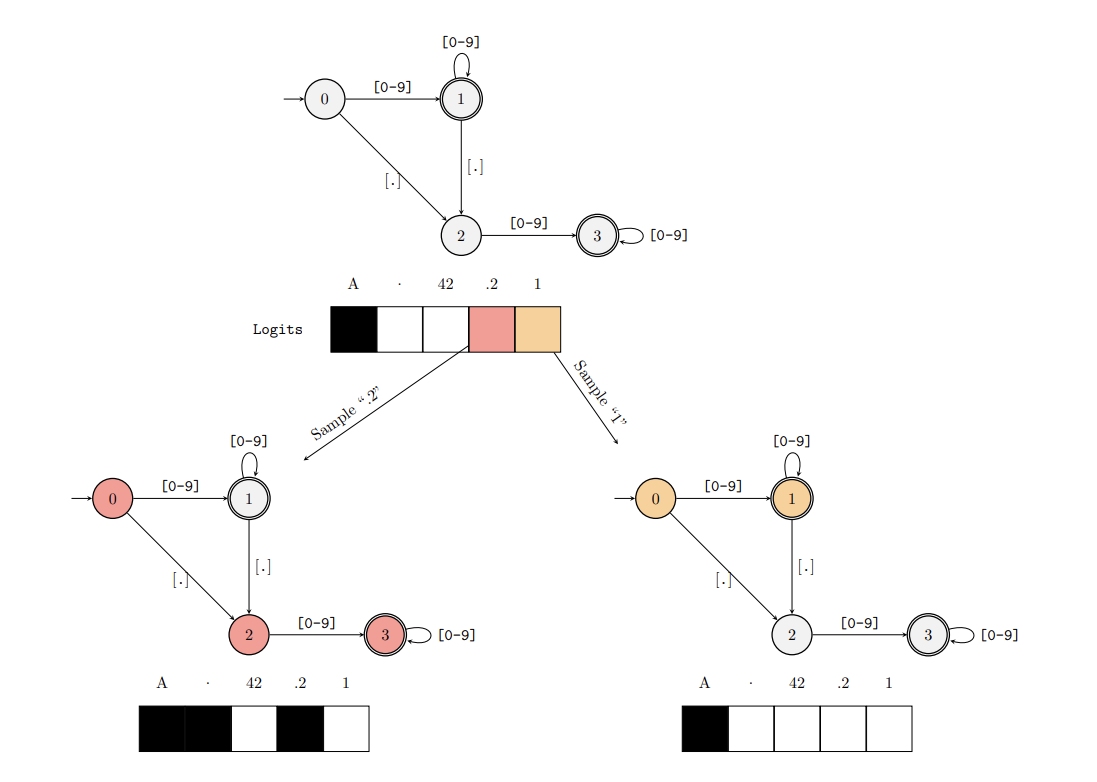
Instead of repeatedly checking tokens against the grammar on the fly, EGG uses a clever pre-processing step. It converts the grammar rules into a Finite-State Machine (FSM), a map of all possible valid states and transitions. Then, it builds an index that maps each state in the FSM to the specific vocabulary tokens that are allowed in that state.
During generation, instead of checking the whole vocabulary, the LLM just looks up the current FSM state in the index and instantly knows the valid next tokens. This drastically speeds up the process, reducing the cost per token from potentially checking the entire vocabulary (O(N)) down to a near-constant time lookup (O(1) on average). EGG makes enforcing complex grammars practical and fast, though its simplest forms might still struggle with the token misalignment nuances without significant online computation.
Making it More Faithful: Grammar-Aligned Decoding (GAD)
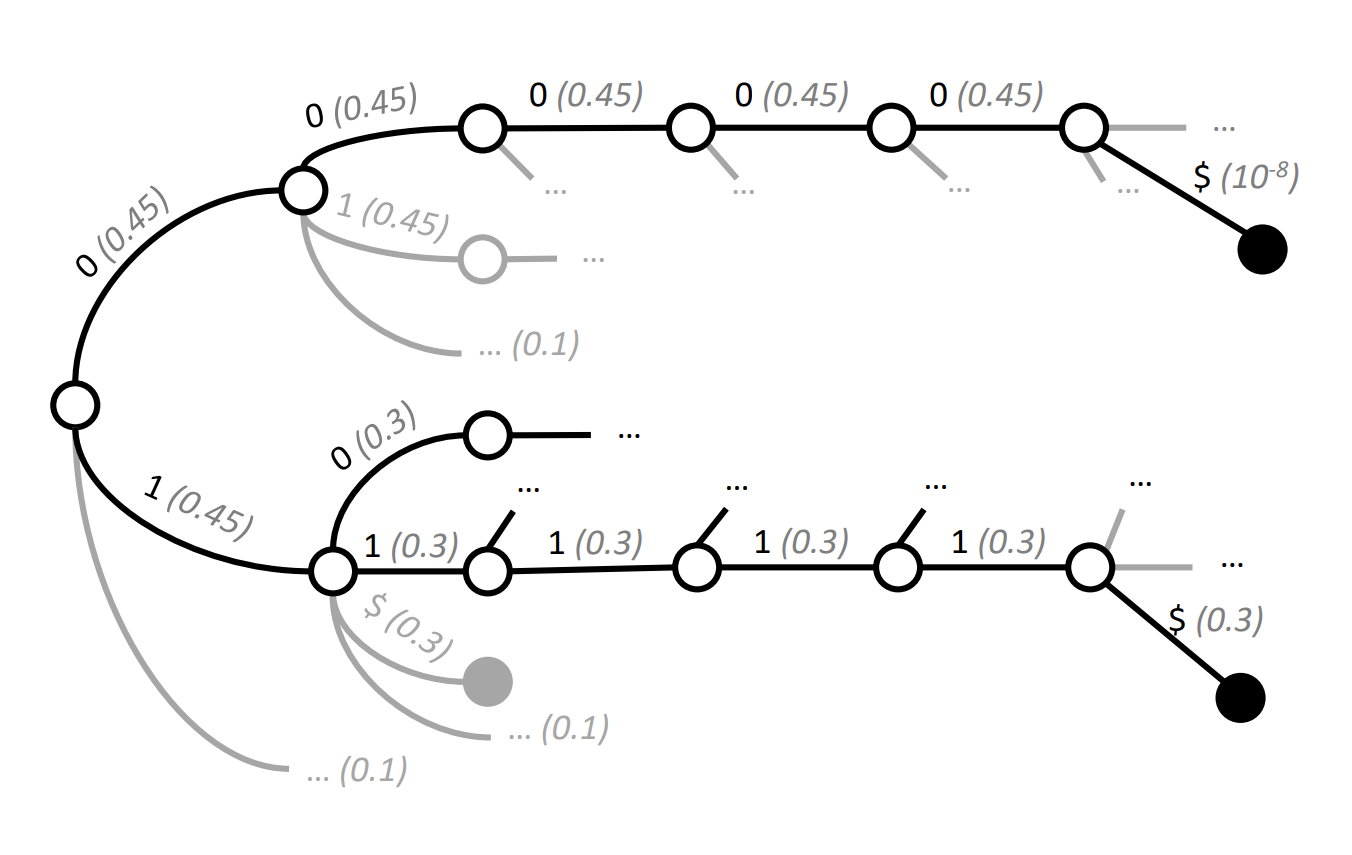
While EGG primarily solves the speed problem, a different challenge remained: does simply masking invalid tokens distort the distribution of what the LLM generates? This is the question addressed by Grammar-Aligned Decoding (GAD).
The GAD paper points out that methods like classic GCD (and by extension, efficient methods like EGG that use the same core masking principle) can inadvertently bias the LLM's output. By forcing the LLM away from certain paths, even if those paths initially looked promising according to the LLM's learned probabilities, we might end up with outputs that are grammatically correct but unlikely or unnatural according to the LLM's own distribution.
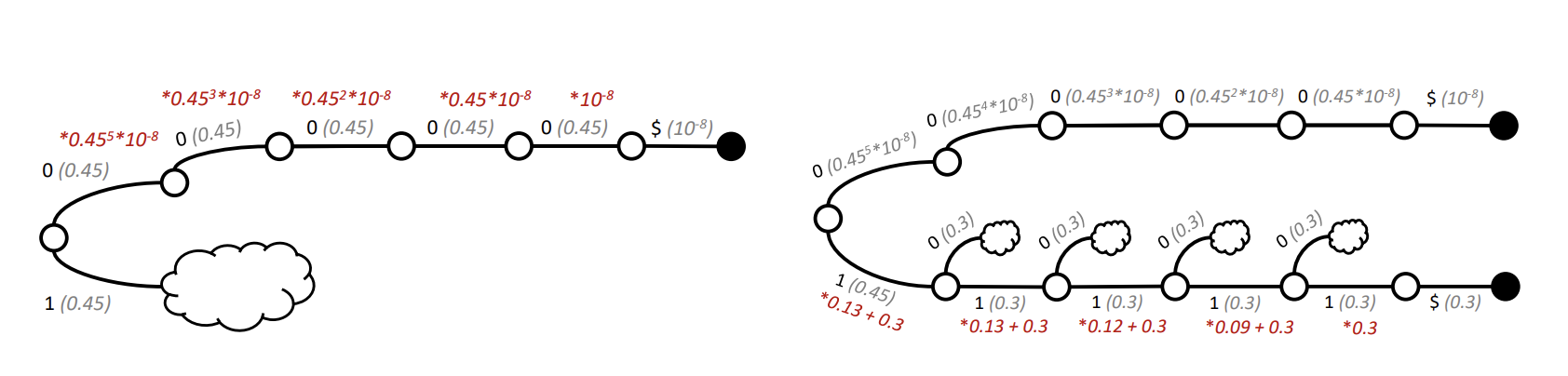
GAD aims for outputs that are not only grammatical but also statistically faithful to the LLM's predictions, conditioned on the grammar. It introduces the concept of Expected Future Grammaticality (EFG) - essentially, the probability that if we let the LLM continue generating from the current point, the resulting full sequence will be grammatically valid.
Classic GCD uses a very simple, binary approximation of EFG (it's either possible or impossible). GAD proposes a more sophisticated algorithm called Adaptive Sampling with Approximate Expected Futures (ASAp). ASAp works iteratively:
- It samples an output using the current best guess for EFG (initially, like GCD).
- It observes where the generation path hit dead ends (non-grammatical sequences).
- It uses the probability mass the LLM assigned to those dead ends to refine its estimate of the EFG for the prefixes along that path.
- It uses this improved EFG estimate for the next sampling iteration.
Over multiple samples, ASAp's EFG approximation gets closer to the true value, allowing it to generate outputs that better reflect the LLM's underlying probability distribution while still satisfying the grammar.
Balancing Offline and Online Efficiency: Flexible and Efficient GCD (FEG)
The quest for efficiency didn't stop with EGG. Some efficient methods require very long offline preprocessing times to build their complex data structures, making them cumbersome for situations where grammars change frequently. This led to the development of approaches like Flexible and Efficient Grammar-Constrained Decoding (FEG).
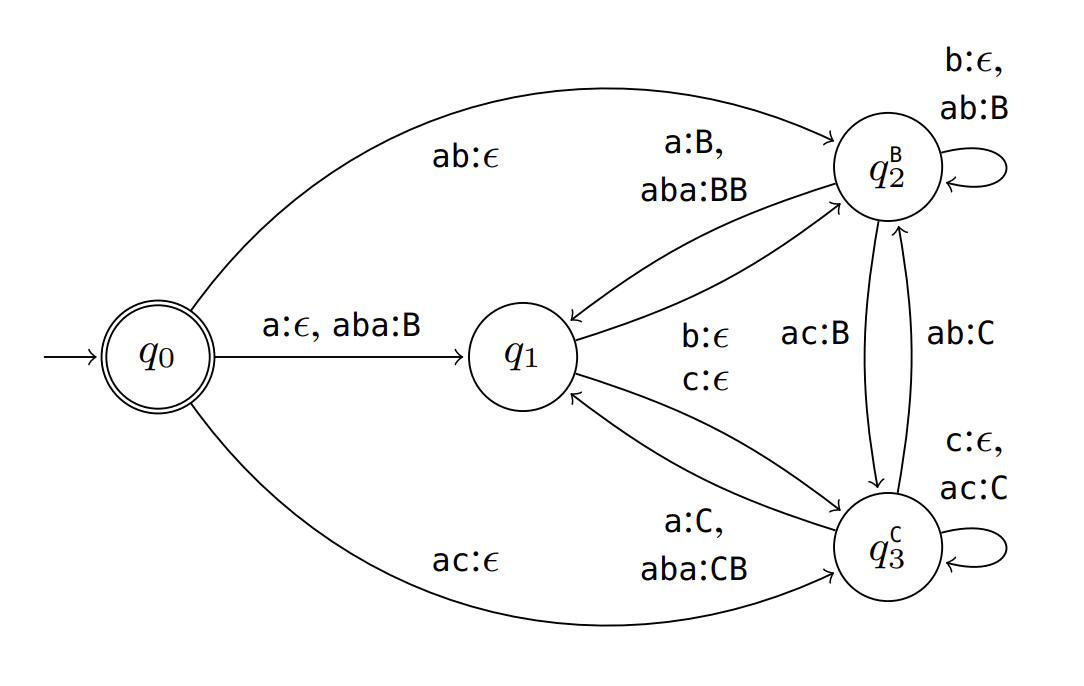
FEG aims for the best of both worlds: low online masking overhead (like the fastest methods) combined with significantly faster offline preprocessing. It tackles the token misalignment problem directly:
- It uses Finite State Transducers (FSTs) to model the relationship between LLM tokens and sequences of grammar terminals, considering the current lexer state.
- It precomputes a "token spanner table" that efficiently stores this mapping.
- It also preprocesses the parser to distinguish between checks that require analyzing the parser's stack ("context-dependent") and those that don't ("always-accepted"), minimizing online computation.
This allows FEG to achieve state-of-the-art online speed while drastically reducing the offline preparation time compared to similarly fast online methods.
Comparing the Approaches
| Feature | Classic GCD | Efficient Guided Generation (EGG) | Grammar-Aligned Decoding (GAD/ASAp) | Flexible & Efficient GCD (FEG) |
|---|---|---|---|---|
| Primary Goal | Grammatical Correctness | Efficiency (Online) + Correctness | Faithfulness + Correctness | Efficiency (Online & Offline) + Flexibility |
| Mechanism | Token Masking | FSM Index + Masking | Adaptive EFG Approx. + Re-weighting | FSTs, Token Spanner Table, Parser Preprocessing + Masking |
| Extension over Classic | Baseline | Speed via efficient lookups | Accuracy via distribution alignment | Balances offline/online costs, handles token misalignment |
| Probability Influence | Masks invalid tokens (potential bias) | Masks invalid tokens (potential bias) | Re-weights valid tokens based on approx. EFG | Masks invalid tokens (potential bias) |
| Key Improvement | Guarantees structure | Drastically improved online speed | Improved faithfulness to LLM distribution | Fast online speed w/ faster offline setup |
| Trade-offs | Slow; struggles w/ misalignment | High online cost (per FEG); basic forms may not handle misalignment well | Requires multiple samples for convergence | Doesn't address faithfulness like GAD |
Conclusion
Choosing the right approach depends on your priorities:
- If you need guaranteed grammatical output and the absolute fastest online generation is the main goal, and you can tolerate potentially high offline costs or simpler grammars, approaches derived from EGG or methods like FEG are strong contenders.
- If you need a balance of fast online speed and reasonable offline setup times, especially if your grammars change often (like in program synthesis), FEG offers a compelling advantage.
- If you need outputs that not only follow the rules but also accurately reflect the LLM's learned likelihoods (perhaps for tasks requiring nuanced or diverse structured outputs), GAD (ASAp) provides a path towards greater faithfulness, albeit potentially at the cost of requiring more sampling iterations.
Understanding these different flavors of grammar-constrained decoding GCD, EGG, GAD, and FEG, helps us better control and leverage the power of LLMs for generating precise, efficient, and faithful structured information.

