Exploring the "Latent Dunning-Kruger" Effect for Grokking Meta-Optimizers


In this ongoing research, we propose that the Dunning-Kruger effect, a statistically demonstrated phenomenon in human learning, has a striking analogy in deep learning. Specifically, when we look at models undergoing grokking (an abrupt shift from memorization to generalization), we observe hysteresis-like curves reminiscent of both:
- Dunning-Kruger curves, where learners exhibit overconfidence early on, become disillusioned upon realizing the complexity, and eventually achieve true mastery with more realistic confidence.
- Phase-transition diagrams in physics (e.g., magnetic hysteresis in ferromagnets), where a material remains in one state until crossing a critical threshold, then “flips” to another stable phase.
We hypothesize that these phenomena are manifestations of the same underlying dynamic: a latent learning process evolving in a path-dependent manner—much like matter transitioning between phases. By drawing on the Dunning-Kruger analogy and hysteresis from physics, we aim to develop meta-optimization strategies that track (and possibly shape) a model’s “latent Dunning-Kruger curve” during training, thus potentially boosting generalization and reducing compute.
Background and Motivation
Hysteresis in Physics
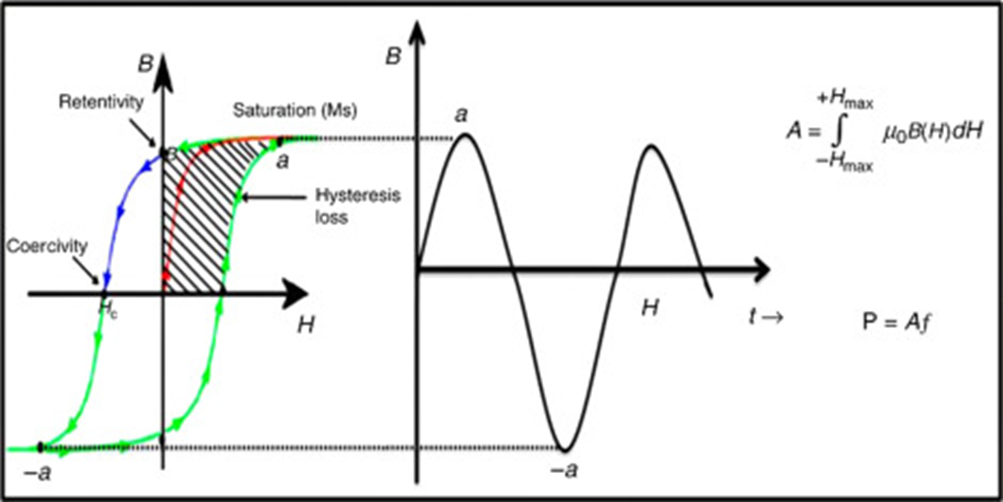
- Hysteresis describes how a system’s internal state depends on its history; for example, the magnetization of ferromagnetic materials lags behind the changing magnetic field, often producing characteristic S-shaped loops.
- Hysteresis Loss quantifies the energy dissipated in a full cycle of magnetization/demagnetization, this underscores path-dependent phase transitions, where returning to the initial state can require extra energy or time.
The Dunning-Kruger Effect in Humans
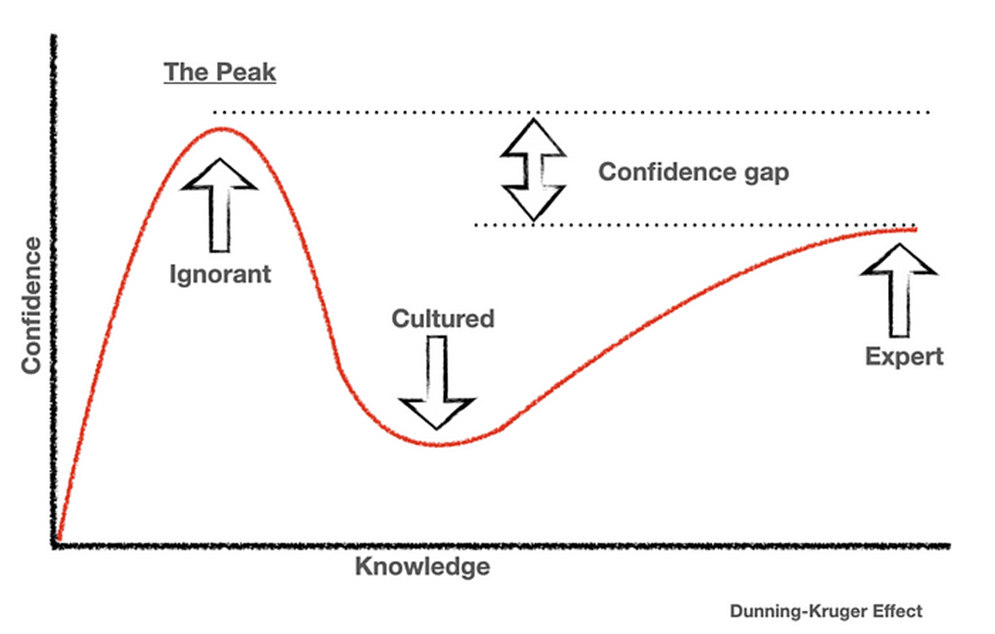
- Empirical studies show that human learners often overestimate their abilities with minimal knowledge, then suffer a dip in confidence upon recognizing the complexity, and finally settle into an expert plateau of competence.
- Visually, this “confidence vs. knowledge” curve features an early spike, a valley, and a gradual climb akin to the loop-like or S-curve form seen in physical hysteresis diagrams (albeit with different axes and interpretations).
Grokking: Memorization to Generalization
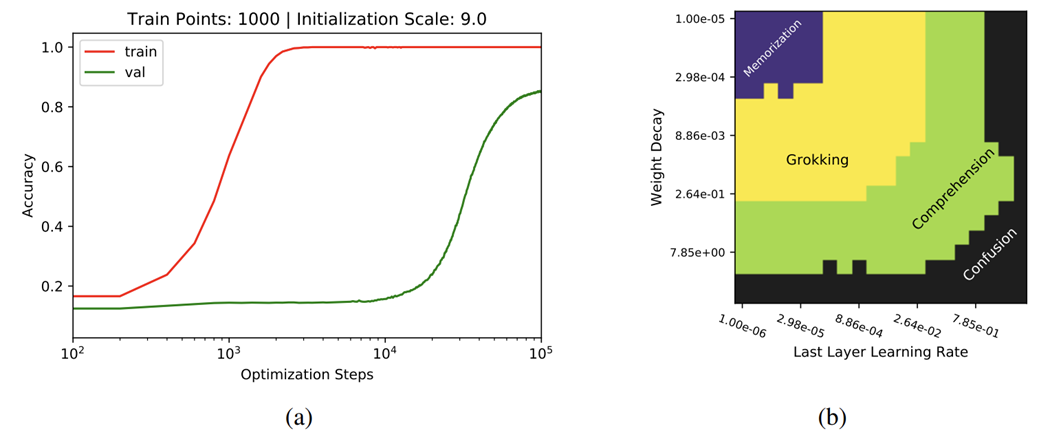
- Grokking refers to an abrupt shift from near-random validation performance to near-perfect generalization after extended training, even when training accuracy was perfect early on.
- From a physics-inspired viewpoint, this is analogous to a phase transition: the system remains stuck in one “phase” (memorization) until some critical condition is reached, triggering a sudden shift to a “generalization” phase.
A Unified Perspective
By observing that:
- Hysteresis curves,
- Dunning-Kruger confidence curves, and
- Learning phase transitions (like grokking)
exhibit similar S-curve or loop-like shapes, it empirically suggests there might be shared physical laws underlying these dynamics. In other words, the latent Dunning-Kruger pattern in neural networks could be harnessed to predict or steer the moment at which a model transitions from memorization to genuine comprehension to optimize the learning process.
Research Aims
- Formalize the Analogy
- Construct a mapping between the Dunning-Kruger “confidence vs. knowledge” axis and the model’s training process.
- Demonstrate how the memorization–grokking–comprehension stages in ML mirror the ignorant–overconfident–expert progression observed in human learners.
- Hysteresis-Style Analysis of Training
- Treat the training process as path-dependent, identifying potential “loops” or S-curves when varying hyperparameters or epochs.
- Investigate whether there is an “energy cost” or “unlearning cost” (akin to hysteresis loss) associated with flipping from memorization to generalization.
- Defining a “Latent Dunning-Kruger” Index
- Track a Confidence Index (e.g., difference between training accuracy and validation accuracy, or logit margins) against a Knowledge Index (e.g., a measure of complexity actually mastered).
- Look for a peak in confidence before true mastery, resembling the classic Dunning-Kruger spike.
- Meta-Optimizer for Accelerating Grokking
- If we can detect or predict these curves, we could intervene with hyperparameter adjustments (learning rate, weight decay, regularization) to hasten the transition to comprehension.
- Explore whether reducing the “hysteresis loop” size (e.g., limiting overconfidence) shortens training time or reduces compute costs.
- Extended Implications
- Examine whether a “latent Dunning-Kruger profile” also helps explain overfitting, catastrophic forgetting, or other anomalies.
- Investigate parallels with human learning data, do smaller networks exhibit quicker overconfidence, akin to novice human learners?
Outline
- Phase Diagram Approach
- Conduct experiments on known grokking tasks (like modular arithmetic).
- Plot training vs. validation accuracy over many epochs and hyperparameters, searching for loop-like transitions reminiscent of hysteresis.
- Quantifying the Curves
- Define a Confidence vs. Knowledge space.
- Examine how the curve evolves as training proceeds, noting “overconfident” peaks, subsequent dips, and eventual stable mastery.
- Use metrics from hysteresis (e.g., loop area) to see if they correlate with training stability or final generalization quality.
- Meta-Optimizer Prototyping
- Steer regularization or other training specific characteristics using the confidence gap and the statistically estimated position on the curve.
- Evaluate time-to-generalization and test accuracy against standard baselines (SGD, Adam, AdamW, etc.).
- Scaling & Validation
- Move beyond toy tasks to moderate-scale data.
- Analyze whether the shape of these Dunning-Kruger/grokking/hysteresis loops remains consistent.
- Integration with SETOL/WeightWatcher
- Employ a meta-analysis of the model’s spectral properties during the dynamic training phases of a small LLM grokked model, using SETOL theory and the WeightWatcher framework.
- Track changes in singular values, power-law exponents, or other spectral metrics that might signal an impending phase transition or “overconfidence spike,” aligning with the proposed Dunning-Kruger phenomenon.
- Comparisons with Human Studies
- Where possible, align model-based “confidence vs. knowledge” plots to known human Dunning-Kruger data from statistical studies, exploring direct or scaled analogies.
Potential Outcomes
- Accelerated Grokking
By identifying the “overconfident but ignorant” zone early, we might steer models towards real comprehension, saving compute and limiting overfitting. - Unified Theory of Phase Transitions
Building stronger links between physics-based hysteresis, psychological learning curves, and machine learning could highlight how systems traverse from ignorance to mastery. - Novel Diagnostics
Introducing “confidence vs. knowledge” loops and hysteresis-based metrics may become standard tools for diagnosing or predicting unstable training regimes, overfit, or slow generalization. - Cross-Disciplinary Insights
If robust analogies hold, it might inform pedagogical strategies in human learning and lead to theoretical breakthroughs about how complex systems learn.
Challenges and Open Questions
- Defining “Confidence” and “Knowledge”: These are inherently abstract concepts, multiple definitions might be tested (e.g., logit margins, entropies, alignment scores).
- Complex Model Behaviors: Large LLMs can undergo multiple mini-phase transitions; the neat single-loop analogy may be an oversimplification.
- Computational Overheads: Real-time tracking of these indexes could be expensive, especially if it requires extra passes or instrumentation.
- Proving True Equivalence: Even if shapes match, do they arise from identical mechanisms (as in physical hysteresis or human cognition)? Demonstrating fundamental equivalences is nontrivial. A direct mathematical derivation should be explored within the SETOL framework theory.
Conclusion
By merging insights from Dunning-Kruger psychology, grokking-style learning phase transitions, and phase hysteresis in physics, this research aims to uncover a latent Dunning-Kruger curve within deep neural networks. By employing a meta-analysis using SETOL theory and WeightWatcher framework during the dynamic training of a small LLM model, we seek to capture spectral signals that anticipate or mirror the overconfidence–dip–mastery arc. If validated, it could lead to meta-optimizers that systematically reduce overconfidence and accelerate true comprehension, a boon to large-scale model training efficiency. More profoundly, such a unification of ideas may uncover universal patterns underlying how complex systems (whether humans or neural nets) transition from ignorance and illusion to mastery and insight.

